
SQL vs NoSQL
Há quem ache que com o surgimento do NoSQL, todos os sistemas deveriam ter deixado de usar bancos relacionais. Porém sabemos que esta afirmação não corresponde à realidade, principalmente em sistemas corporativos. Isto não significa que sair trocando um PostgreSQL por MongoDB ou Oracle pelo Cassandra, em qualquer sistema, seria o mundo perfeito ou resolveria magicamente quaisquer necessidades.
Mas a questão na qual queremos chegar é a seguinte: observado o fato de que bancos relacionais e não relacionais deverão coexistir, como podemos tentar tirar o melhor proveito dos dois mundos?
Essa questão nos acompanha aqui na Join há um bom tempo. O estudo de caso abaixo é um exemplo de solução utilizando um banco relacional (Oracle) e um não relacional (ElasticSearch) sob um sistema Java EE, buscando entregar a melhor solução possível dentro de um determinado cenário.
Nosso desafio
Em um grande sistema do setor jurídico no qual estávamos envolvidos, já nas últimas sprints, surgiu a necessidade da criação de vários relatórios que mais pareciam um BI:
-
grande volume de dados;
-
muitas combinações de filtros possíveis, alguns destes em campos textuais de grande extensão (CLOB);
-
alta complexidade de informação;
-
identificação do usuário com um modelo de layout muito específico;
-
tempo para geração do relatório deveria ser de no máximo alguns segundos.
Já havíamos desenvolvido outros relatórios para este sistema e, comparando a proporção de dados, tabelas relacionadas e totalizadores requisitados, ficava claro que mesmo otimizando as consultas, o tempo de execução destes novos relatórios seria alto.
Para resolver este problema, foi levantada a hipótese de que os dados destes relatórios deveriam ser consumidos de uma base NoSQL, com desempenho superior na busca de dados e que, principalmente, tivesse recursos especializados para busca textual.
A escolha pelo ElasticSearch
A equipe analisou, testou, discutiu diferentes opções e escolheu o ElasticSearch (ES), uma tecnologia open source com indexação e busca distribuída, levando em consideração os seguintes critérios:
-
ES fornece uma API REST pronta para entrada e saída de dados;
-
utilizado por grandes players do mercado nacional e internacional;
-
documentação disponível cobria nossas necessidades;
-
comunidade grande e ativa;
-
produtividade;
-
sem custos adicionais ao cliente.
Outras soluções avaliadas também contavam com banco não relacional ou API de consulta, mas consideramos a API do ES como a mais completa e prática.
Ela nos forneceu todos recursos necessários para criar e remover índices (o equivalente a uma base ou schema de um banco relacional), efetuar as operações de CRUD sobre os dados do Elastic e enviar as informações já pré-configuradas através de um JSON com a mesma estrutura do DTO utilizado em nosso relatório. Isto facilitou muito na integração com o sistema desenvolvido para o nosso cliente.
É comum que o ES seja utilizado dentro da sua stack completa, a ELK (ElasticSearch/Logstash/Kibana). O Logstash é uma ferramenta para ingestão e enriquecimento de dados, inicialmente projetada para tratamento e envio de logs, mas que com o tempo passou a ser utilizada para diversos tipos de fontes de dados. Já o Kibana provê uma interface de visualização e análise dos dados presentes no ES.
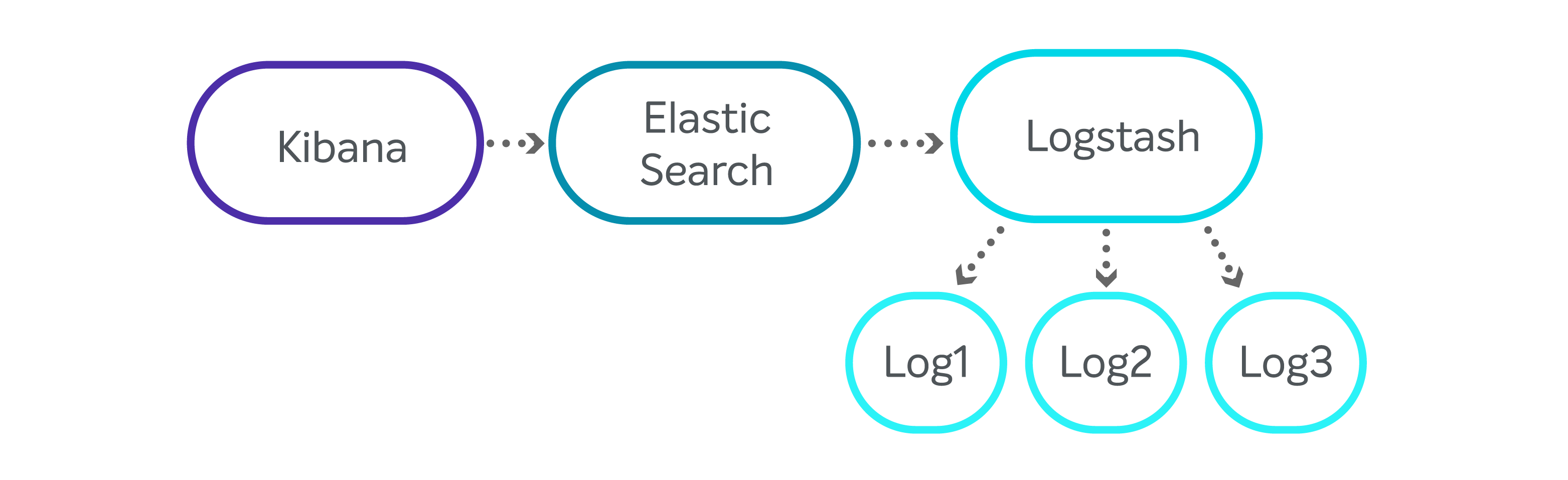 Desenho padrão da comunicação entre a stack ELK
Desenho padrão da comunicação entre a stack ELK
A equipe, entretanto, optou por utilizar somente o ES neste projeto, pois ele já atenderia as necessidades. Os dados poderiam ser tratados por um serviço da aplicação e enviados via API diretamente ao ES, dispensando a necessidade do Logstash.
Da mesma forma, o Kibana não foi adotado, pois era requisito do cliente que a forma de visualização dos dados seguisse um layout muito específico, que geraria grande esforço de customização e que, além disso, já contava com frameworks no sistema, mais adequados para a tarefa, de acordo com a experiência do time.
Ainda sobre o ES, vale destacar o seu desempenho, principalmente com textos. Classificada pela Elastic como “near real time”, sua performance se apoia em diversos mecanismos.
Arquitetura distribuída
A arquitetura do ES foi feita para facilitar a escalabilidade e o crescimento horizontal. Você já deve ter experimentado a situação em que a lentidão de uma ou várias aplicações se devia ao multiprocessamento de vários processos no mesmo servidor.
Muitas vezes, a forma mais efetiva de resolver essa lentidão é separar as aplicações em diferentes máquinas, sejam físicas ou virtuais.
Com o ES é possível que você consulte a informação a partir de um cluster com “n” nodes, os quais podem ser diferentes máquinas onde serão armazenadas informações.
Em cada node, um mesmo indice poderá definir “n” shards, que são semelhantes a particionamentos dos dados dentro do node. Os shards também podem contar com réplicas, que fornecem maior resiliência aos dados.
Inverted Index
Ao invés de armazenar apenas um id e colunas de valor, como um banco de dados relacional tradicional, o Elastic armazena “termos” (palavras), sua quantidade de repetições e documentos onde ocorrem.
Desta forma, em uma busca por texto específico, ao invés de realizar um fullscan em talvez milhões de registros, ele pode localizar diretamente apenas os registros onde as palavras filtradas de fato ocorrem.
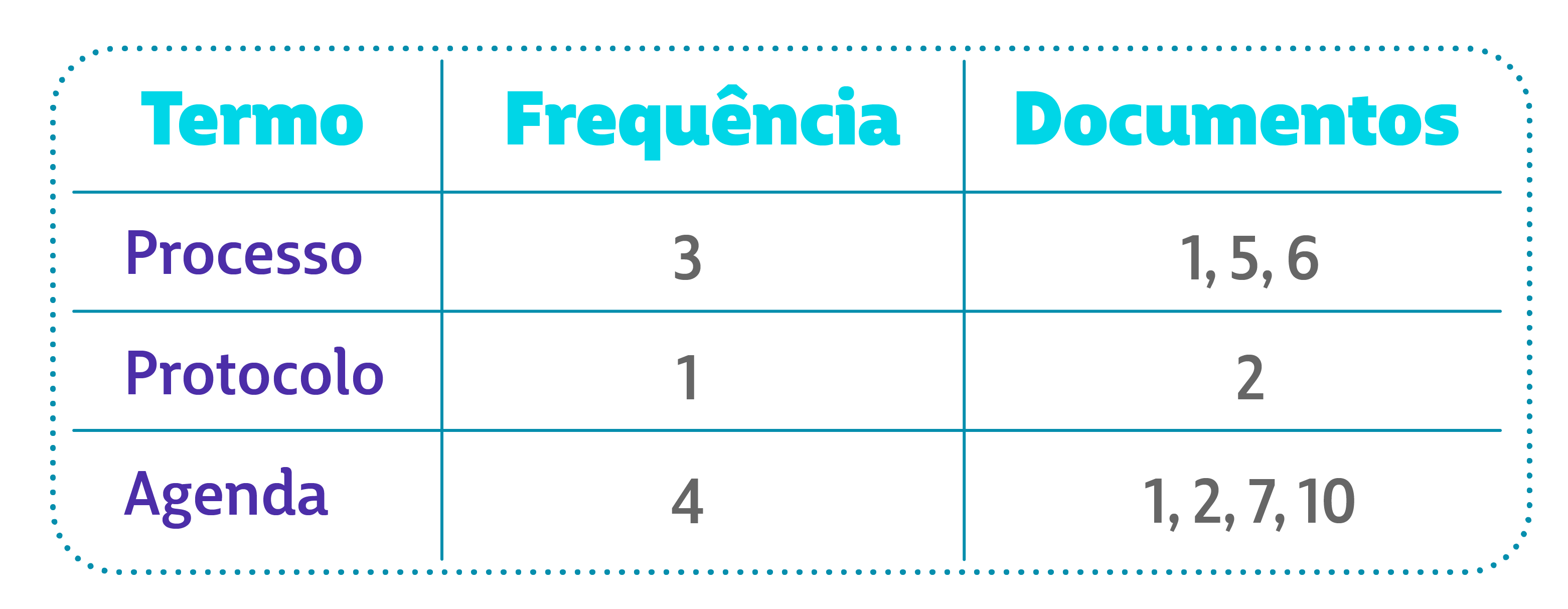 Exemplo de organização do índice invertido
Exemplo de organização do índice invertido
Indo ainda além do inverted index, o ES possui um algoritmo de várias camadas de critério para scoring de similaridade. Nas últimas versões do ES, este algoritmo é chamado BM25.
 Fórmula do BM25
Fórmula do BM25
Confira mais informações sobre o algoritmo diretamente no site da Elastic.
Integração na prática
 Stack integração
Stack integração
A equipe buscou criar essa integração da forma mais simples possível:
criar rotinas agendadas que consultam os dados do banco relacional do sistema e verificam novos registros;
preparar e indexar as informações no ES;
consultar os dados do relatório do ES ao invés do Oracle.
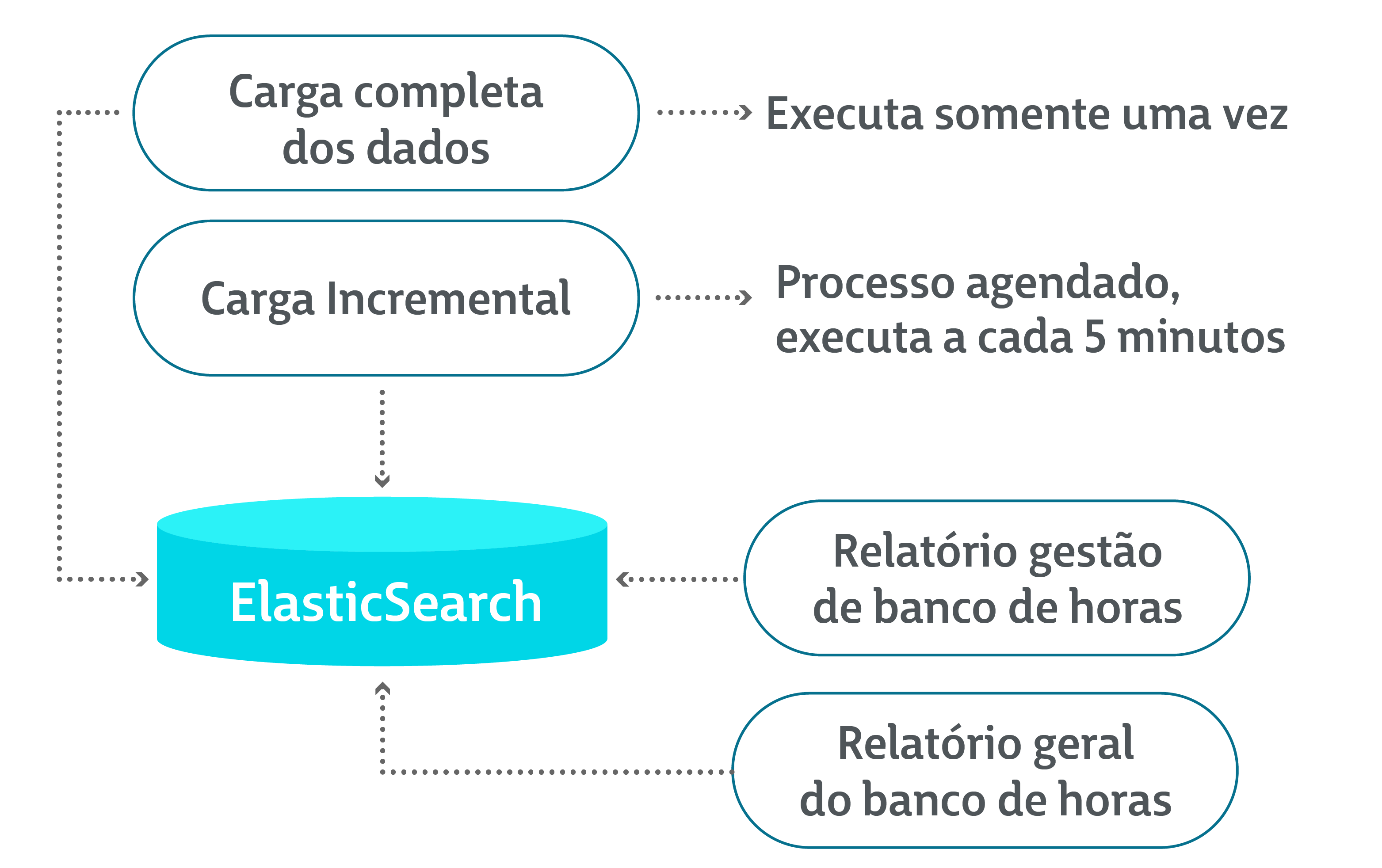
Para iniciar o processo foi criada na aplicação Java uma rotina do Spring de carga completa de dados. A rotina faz a consulta de todas essas informações e prepara os dados para o envio ao ES.

Essa carga completa tem a função de popular os dados tanto no primeiro uso quanto no momento de recriar este banco-espelho em eventuais necessidades de restauração dos dados da base Oracle.
No nosso caso, isso dispensou a necessidade da criação de rotinas de backup específicas para os dados do ES, porém ele fornece recursos para criação de snapshots.
Com os dados prontos para serem inseridos, é chamado um outro serviço Java que faz a integração com a API do ElasticSearch. O serviço realiza os seguintes passos:
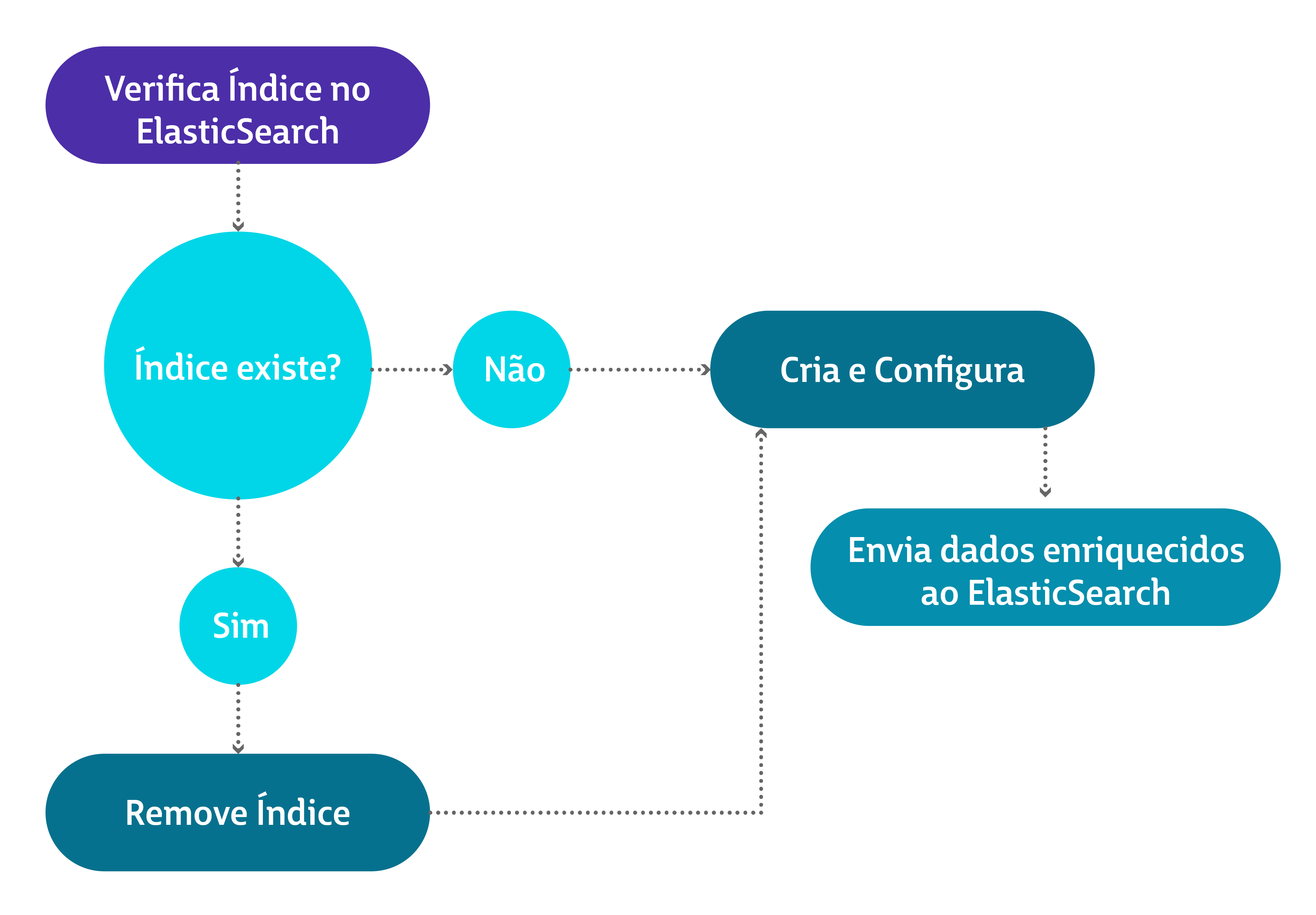
Serviço de ingestão de dados
A Elastic fornece bibliotecas para integração com diversas linguagens. No caso deste projeto, foram utilizados os artefatos “elasticsearch-rest-client” e “elasticsearch-rest-high-level-client”, disponíveis no repositório central maven.
Com a carga completa finalizada, há uma segunda carga, que faz incrementos de novos lançamentos após a data de corte. Ela tem o processamento bem semelhante ao da carga principal, porém só envia informações novas ou que foram alteradas, fazendo, assim, a atualização dos dados do ES.
Para controlar quais são as novas informações a enviar e quais já foram processadas, foi criada uma tabela no Oracle que mantém o histórico de todo processamento já realizado.
Quando novos registros relacionados ao relatório que consulta o ES são adicionados ou atualizados, eles também são gravados na tabela de controle. Assim, quando a rotina incremental agendada é executada, é possível saber quais dados deverão ser sincronizados.
Conclusão
A equipe ficou muito satisfeita com os recursos da versão 7.5 do ElasticSearch e a integração entre banco relacional e não relacional em um mesmo sistema. O resultado foi efetivo no ganho de desempenho final e na busca de manter a geração dos relatórios dentro da expectativa e necessidade do cliente.
E no seu projeto, como tem sido os resultados da união entre SQL e NoSQL?


